一致性哈希算法在1997年由麻省理工学院的Karger等人在解决分布式Cache中提出的,设计目标是为了解决因特网中的热点(Hot spot)问题,初衷和CARP十分类似。一致性哈希修正了CARP使用的简单哈希算法带来的问题,使得DHT可以在P2P环境中真正得到应用。
一致性hash的原理
现在一致性hash算法在分布式系统中也得到了广泛应用,研究过memcached缓存数据库的人都知道,memcached服务器端本身不提供分布式cache的一致性,而是由客户端来提供,具体在计算一致性hash时采用如下步骤:
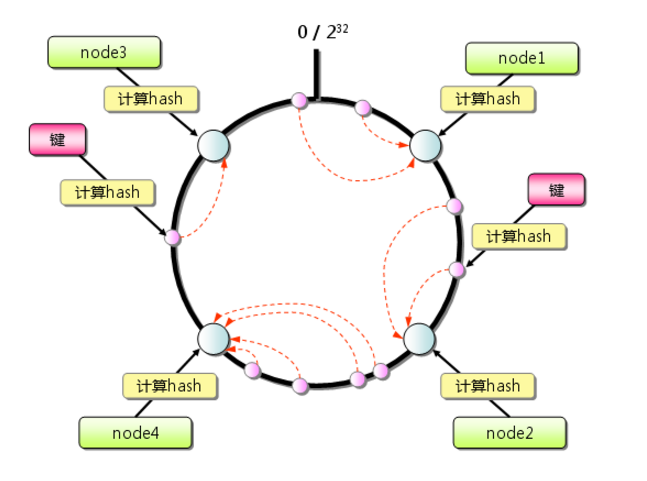
首先求出memcached服务器(节点)的哈希值,并将其配置到0~232的圆(continuum)上。
然后采用同样的方法求出存储数据的键的哈希值,并映射到相同的圆上。
然后从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务器上。如果超过232仍然找不到服务器,就会保存到第一台memcached服务器上。
从上图的状态中添加一台memcached服务器。余数分布式算法由于保存键的服务器会发生巨大变化而影响缓存的命中率,但Consistent Hashing中,只有在园(continuum)上增加服务器的地点逆时针方向的第一台服务器上的键会受到影响,如下图所示:
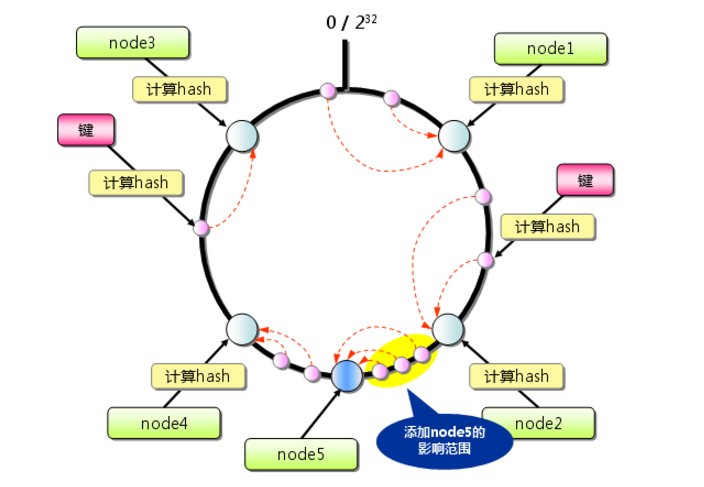
值得注意的是,一致性哈希算法在服务节点太少时,容易因为节点分部不均匀而造成数据倾斜问题。
优化方法
通过增加虚拟节点来解决数据倾斜问题
一致性哈希算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点。具体做法可以在服务器ip或主机名的后面增加编号来实现。例如上面的情况,可以为每台服务器计算三个虚拟节点,于是可以分别计算 “Node A#1”、“Node A#2”、“Node A#3”、“Node B#1”、“Node B#2”、“Node B#3”的哈希值,于是形成六个虚拟节点:
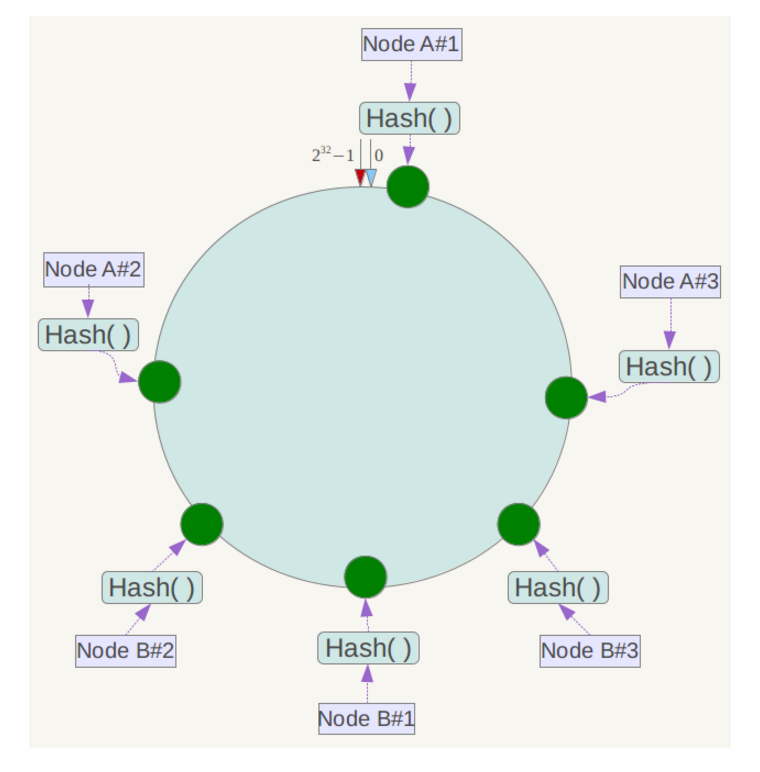
当我们添加的虚拟节点越多,虚拟节点分布就越平均,数据倾斜的程度就越小。我们一般建议虚拟节点大概在200个左右。但是问题来了,如果大量的虚拟节点,节点的查找性能就成为必须考虑的因数。
使用红黑树来加快查找速度
红黑树已经广泛应用,其原理就不再叙述了。
实现一致性哈希
go语言版本
1 | package hashring |